이 페이지에 들어가서 F12 키를 누르면 아래와 같이 html 코드를 확인할 수 있습니다.
마우스로 html 코드에 올려 놓으면, 그 코드가 왼쪽의 어느 영역을 포함하는지 확인할 수 있습니다.
tbody id = "regularTeamRecordList_table"을 가진 테이블에 순위 정보가 있는 것을 확인할 수 있습니다.
아래 코드를 통해, regularTeamRecordList_table 테이블의 구조를 알아보도록 하겠습니다.
각 팀을 tr 태그로 구분하였고, 그 하위에 순위는 td, 나머지 구단이름, 경기수, 승, 패, 무승부 등등은 td 태그로 구분하였음을 알 수 있습니다.
url = "https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser')
print(soup) #파싱된 html 출력
BeautifulSoap 모듈의 find / findAll 함수를 이용해 정보 추출하기
우선 "regularTeamRecordList_table" 테이블을 찾고, 그 안에 있는 모든 "tr" 태그(각 팀 정보)를 찾습니다.
각 팀 정보에는 순위 정보를 가진 th 태그 하나와 그 밖에 정보를 가지고 있는 td 태그가 있습니다.
순위 정보를 가진 th 태그 안에 strong 태그가 있어, 한번 더 find를 하고, strong 태그 안의 정보를 가져옵니다.
그리고 다른 정보들은 모두 td 태그 하위의 span 태그에 있음을 알 수 있습니다.
그래서 tr 태그 아래의 모든 span 태그 정보를 가져옵니다.
첫번째 span 태그로부터 구단 정보,
두번째 span 태그로부터 경기수,
세번째 span 태그로부터 승,
네번째 span 태그로부터 패,
다섯번째 span 태그로부터 무승부 정보를 가져옵니다.
for tr_tag in soup.find(id='regularTeamRecordList_table').find_all('tr'):
th_tag = tr_tag.find('th')
strong_tag = th_tag.find('strong')
lank = strong_tag.get_text()
span_tag = tr_tag.findAll('span')
team = span_tag[0].get_text()
total = span_tag[1].get_text()
win = span_tag[2].get_text()
lose = span_tag[3].get_text()
draw = span_tag[4].get_text()
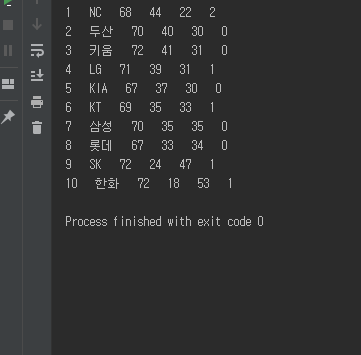
그리고 가져온 정보를 출력하도록 하면 맨 위의 이미지와 같이 순위 정보를 표시할 수 있습니다.
전체 코드
from bs4 import BeautifulSoup
import urllib.request as req
url = "https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser')
#print(soup) #파싱된 html 출력
for tr_tag in soup.find(id='regularTeamRecordList_table').find_all('tr'):
th_tag = tr_tag.find('th')
strong_tag = th_tag.find('strong')
lank = strong_tag.get_text()
span_tag = tr_tag.findAll('span')
team = span_tag[0].get_text()
total = span_tag[1].get_text()
win = span_tag[2].get_text()
lose = span_tag[3].get_text()
draw = span_tag[4].get_text()
print(lank, " ", team, " ", total, " ", win, " ", lose, " ", draw)
쉘 코드를 사용하기 위하여 함수의 반환 주소를 단순히 덮어 쓰는 방법은 사용할 수 없고, 버퍼에 할당된 포인터 값을 덮어 쓰는 공격 방법이다.
스택 버퍼 오버플로우(Stack Buffer Overflow)
프로그램에서 특정 함수를 실행시키면 스택에 이전 함수로 돌아가기 위한 주소가 기록되고, 버퍼에 큰 값을 넣게 되면 이 스택 영역을 침범하게 됩니다. 리턴 주소가 들어갈 곳에 쉘코드나 다른 프로그램의 주소를 넣으면 그것이 실행되게 되는데, 이를 스택 버퍼 오버플로우라고 합니다.
관련 문제
10회 다음 지문에서 설명하는 공격은? 3 [보기] - 이 공격에 사용되는 메모리 영역은 malloc, free 등의 함수로 제어함 - 쉘 코드를 사용하기 위하여 함수의 반환 주소를 단순히 덮어 쓰는 방법은 사용할 수 없고, 버퍼에 할당된 포인터 값을 덮어 쓰는 방법이 일반적으로 사용됨
① 스택 버퍼 오버플러우 ② 레이스 컨디셔닝 ③ 힙 버퍼 오버플로우 ④ RTL(Return To Libc)
8회 스택 버퍼 오버플로우 공격의 수행절차를 순서대로 바르게 나열한 것은?3
[보기] ㄱ. 특정 함수의 호출이 완료되면 조작된 반환 주소인 공격셸 코드의 주소가 반환된다. ㄴ. 루트 권한으로 실행되는 프로그램 상에서 특정 함수의 스택 버퍼를 오버플로우시켜서 공격 셸 코드가 저장되어 있는 버퍼의 주소로 반환 주소를 변경한다. ㄷ. 공격 셸 코드를 버퍼에 저장한다. ㄹ. 공격 셸 코드가 실행되어 루트 권한을 획득하게 된다. ① ㄱ→ㄴ→ㄷ→ㄹ ② ㄱ→ㄷ→ㄴ→ㄹ ③ ㄷ→ㄴ→ㄱ→ㄹ ④ ㄷ→ㄱ→ㄴ→ㄹ
7회 다음 내용은 어느 공격기법에 관한 설명인가?1
보기 침해 시스템을 부넉하던 중 test라는 계정의 홈 디렉터리에서 C언어로 작성된 Exploit 코드와 컴파일된 바이너리파일을 발견할 수 있었다. 이 Exploit은 stack에 할당되어진 변수에 데이터 사이즈를 초과 입력하여 RET를 덮어 씌워 ShellCode를 실행하는 코드였다. ① Buffer Overflow ② Format String ③ Race condition ④ Brute force
6회 메모리 오류를 이용해 타깃 프로그램의 실행 흐름을 제어하고, 최종적으로는 공격자가 원하는 임의의 코드를 실행하는 것을 무엇이라 하는가? 2 ① 포맷 스트링 ② 버퍼 오버플로우 ③ 레이스 컨디셔닝 ④ 메모리 단편화
4회 다음 중 버퍼오버플로우 대한 설명으로 올바르지 못한 것은?1 ①버퍼에 저장된 프로세스 간의 자원 경쟁을 야기해 권한을 획득하는 기법으로 공격하는 방법이다. ②메모리에 할당된 버퍼의 양을 초과하는 데이터를 입력하여 프로그램의 복귀 주소를 조작하는 기법을 사용하여 해킹을 한다. ③스택 버퍼오버플로우와 힙 오버플로우 공격이 있다. ④버퍼오버플로우가 발생하면 저장된 데이터는 인접한 변수영역까지침범하여 포인터 영역까지 침범하므로 해커가 특정코드를 실행하도록 하는 공격기법이다.
8회 버퍼 오버플로우 공격의 대응수단으로 적절하지 않은 것은? 2 ① 스택상에 있는 공격자의 코드가 실행되지 못하도록 한다. ② 프로세스 주소 공간에 있는 중요 데이터 구조의 위치가 변경되지 않도록 적재 주소를 고정시킨다. ③ 함수의 진입(entry)과 종료(exit) 코드를 조사하고 함수의 스택 프레임에 대해 손상이 있는지를 검사한다. ④ 변수 타입과 그 타입에 허용되는 연산들에 대해 강력한 표 기법을 제공하는 고급수준의 프로그래밍 언어를 사용한다.