반응형
파이썬 머신러닝 / k-최근접 이웃 알고리즘(KNN) 알아보기
k-최근접 이웃 알고리즘은 가장 간단한 지도학습 머신러닝 알고리즘으로 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측합니다. 가장 가까운 이웃을 k개를 선택할 수 있고, 둘 이상의 이웃을 선택하였을 경우 레이블을 정하기 위해 더 많은 클래스를 레이블의 값으로 정합니다.
간단하게 파이썬으로 k-최근접 이웃 알고리즘의 성능을 평가해보겠습니다.
먼저 필요한 라이브러리를 가져옵니다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
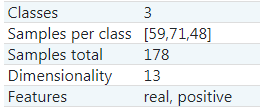
분석을 위한 scikit-learn 라이브러리의 유방암에 대한 데이터셋을 가져오겠습니다.
그리고 데이터는 학습 세트와 테스트 세트로 나누었습니다.
cancer = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.3, stratify=cancer.target, random_state=100)
k-최근접 이웃의 수에 따라 train 세트와 test세트의 정확도를 살펴보기 위해 아래와 같이 변수를 생성하였습니다.
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 101)
최근접 이웃의 수를 1부터 101까지 설정하여 학습 데이터를 가지고, 테스트 데이터의 성능을 평가해보겠습니다.
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(x_train, y_train)
training_accuracy.append(clf.score(x_train, y_train))
test_accuracy.append(clf.score(x_test, y_test))
그리고 이것을 그래프로 그려보겠습니다.
plt.plot(neighbors_settings, training_accuracy, label='train_accuracy')
plt.plot(neighbors_settings, test_accuracy, label='test_accuracy')
plt.ylabel('accuracy')
plt.xlabel('n_neighbors')
plt.legend()
plt.show()
이것을 실행해보면 아래 그래프가 출력됩니다.
그래프로 봐서는 n_neighbors가 10정도일 때, train_accuracy와 test_accuracy가 어느 정도 높게 나오는 것을 볼 수 있습니다.

전체 코드
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
cancer = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.3, stratify=cancer.target, random_state=100)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 101)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(x_train, y_train)
training_accuracy.append(clf.score(x_train, y_train))
test_accuracy.append(clf.score(x_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label='train_accuracy')
plt.plot(neighbors_settings, test_accuracy, label='test_accuracy')
plt.ylabel('accuracy')
plt.xlabel('n_neighbors')
plt.legend()
plt.show()반응형
'파이썬 > 파이썬 사이킷런' 카테고리의 다른 글
| 파이썬 머신러닝 - Kernel PCA를 이용한 비선형 특성의 수 줄이기 (0) | 2020.09.13 |
|---|---|
| 파이썬 머신러닝 - PCA를 이용한 특성의 수 줄이기 (0) | 2020.09.13 |
| 파이썬 머신러닝 Scikit-learn 주요 데이터셋 종류 (0) | 2020.09.13 |