파이썬 웹 크롤링 / BeautifulSoup를 이용한 네이버 스포츠 야구 순위 정보 가져오기
requests 모듈을 이용해 네이버 스포츠 야구 순위를 가진 페이지 코드를 가져옵니다.
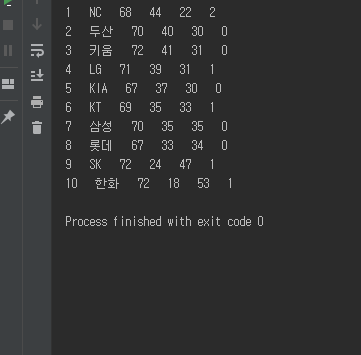
BeautifulSoup 모듈을 이용해 가져온 페이지 코드를 파싱하고, 파싱된 순위 정보를 아래와 같이 표시하는 것을 알아보도록 하겠습니다.
네이버 스포츠 야구 순위 페이지에 대한 html 코드 정보 확인
우선 네이버 스포츠 야구 순위 페이지에 대한 html 코드 정보를 확인해 보겠습니다.
아래 링크는 네이버 스포츠 야구 순위 정보를 표시하는 url입니다.
https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo
네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
이 페이지에 들어가서 F12 키를 누르면 아래와 같이 html 코드를 확인할 수 있습니다.
마우스로 html 코드에 올려 놓으면, 그 코드가 왼쪽의 어느 영역을 포함하는지 확인할 수 있습니다.
tbody id = "regularTeamRecordList_table"을 가진 테이블에 순위 정보가 있는 것을 확인할 수 있습니다.

아래 코드를 통해, regularTeamRecordList_table 테이블의 구조를 알아보도록 하겠습니다.
각 팀을 tr 태그로 구분하였고, 그 하위에 순위는 td, 나머지 구단이름, 경기수, 승, 패, 무승부 등등은 td 태그로 구분하였음을 알 수 있습니다.
url = "https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser')
print(soup) #파싱된 html 출력
BeautifulSoap 모듈의 find / findAll 함수를 이용해 정보 추출하기
우선 "regularTeamRecordList_table" 테이블을 찾고, 그 안에 있는 모든 "tr" 태그(각 팀 정보)를 찾습니다.
각 팀 정보에는 순위 정보를 가진 th 태그 하나와 그 밖에 정보를 가지고 있는 td 태그가 있습니다.
순위 정보를 가진 th 태그 안에 strong 태그가 있어, 한번 더 find를 하고, strong 태그 안의 정보를 가져옵니다.
그리고 다른 정보들은 모두 td 태그 하위의 span 태그에 있음을 알 수 있습니다.
그래서 tr 태그 아래의 모든 span 태그 정보를 가져옵니다.
첫번째 span 태그로부터 구단 정보,
두번째 span 태그로부터 경기수,
세번째 span 태그로부터 승,
네번째 span 태그로부터 패,
다섯번째 span 태그로부터 무승부 정보를 가져옵니다.
for tr_tag in soup.find(id='regularTeamRecordList_table').find_all('tr'):
th_tag = tr_tag.find('th')
strong_tag = th_tag.find('strong')
lank = strong_tag.get_text()
span_tag = tr_tag.findAll('span')
team = span_tag[0].get_text()
total = span_tag[1].get_text()
win = span_tag[2].get_text()
lose = span_tag[3].get_text()
draw = span_tag[4].get_text()그리고 가져온 정보를 출력하도록 하면 맨 위의 이미지와 같이 순위 정보를 표시할 수 있습니다.
전체 코드
from bs4 import BeautifulSoup
import urllib.request as req
url = "https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser')
#print(soup) #파싱된 html 출력
for tr_tag in soup.find(id='regularTeamRecordList_table').find_all('tr'):
th_tag = tr_tag.find('th')
strong_tag = th_tag.find('strong')
lank = strong_tag.get_text()
span_tag = tr_tag.findAll('span')
team = span_tag[0].get_text()
total = span_tag[1].get_text()
win = span_tag[2].get_text()
lose = span_tag[3].get_text()
draw = span_tag[4].get_text()
print(lank, " ", team, " ", total, " ", win, " ", lose, " ", draw)'파이썬 > 파이썬 웹 크롤링' 카테고리의 다른 글
| 파이썬 웹 크롤링 / 네이버 현재 상영영화 정보 가져오기 (0) | 2021.08.25 |
|---|---|
| 파이썬 웹 크롤링 / 네이버 영화 인기검색어 순위 가져오기 (0) | 2021.08.23 |
| 파이썬 웹 크롤링 / 네이버 첫화면 HTML 가져오기 - beautifulsoup Parser와 비교 (0) | 2020.07.29 |