파이썬 머신러닝 scikit-learn 데이터셋 종류
Scikit-learn 라이브러리는 파이썬에서 유명한 머신러닝 라이브러리 중 하나입니다. 이 라이브러리는 머신러닝 알고리즘을 적용할 수 있는 함수들을 제공하며, 다양한 데이터 샘플을 제공합니다. 이번에는 Scikit-learn의 다양한 데이터 샘플을 알아보도록 하겠습니다.

1) sklearn.datasets.load_iris : 꽃 종류 중 하나인 붓꽃 데이터셋
이 데이터셋은 간단하고 유명한 데이터셋 샘플입니다.
종류는 3 종류가 있고, 데이터 샘플은 각 종류마다 50개씩 있습니다.
그리고 모두 150개의 샘플을 가지고 있으며, 특성은 4가지가 있습니다.

2) sklearn.datasets.load_digits : 0부터 9까지의 숫자를 손으로 쓴 이미지 데이터셋
이 데이터셋은 0-9 까지 총 10개의 클래스를 가지고 있습니다. 각 클래스는 180 여개의 샘플 데이터를 가지고 있으며, 총 샘플 데이터는 1797개가 있습니다. 8x8 이미지라 특성은 총 64가지가 있습니다.

3) sklearn.datasets.load_diabetes : 당뇨병 진행도에 대한 데이터셋
이 데이터셋은 총 442개의 샘플 데이터를 가지고 있고, 10개의 특성을 가지고 있습니다. 이 데이터셋은 주로 회귀 분석에 사용되는 데이터셋입니다.

4) sklearn.datasets.load_breast_cancer : 유방암에 대한 데이터셋
이 데이터셋은 총 2개의 클래스를 가지며, 하나의 클래스는 212개의 샘플데이터를 가지고 있으며, 또 다른 하나의 클래스는 357개의 데이터 셋을 가지고 있습니다. 총 30개의 특성을 가지고 있습니다.

5) sklearn.datasets.load_boston : 보스턴 집값에 대한 데이터셋
이 데이터셋은 총 506개의 샘플 데이터를 가지고 있으며, 13개의 특성을 가지고 있습니다. 주로 회귀 분석에 사용됩니다.

6) sklearn.datasets.load_wine : 와인에 대한 데이터셋
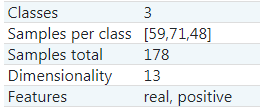
이 데이터셋은 총 3개의 클래스를 가지며, 각 59, 71, 48개의 샘플 데이터를 가지고 있습니다. 또한 13개의 특성을 가지고 있습니다.
Scikit-learn의 데이터셋 뿐 아니라 라이브러리에 대한 정보는 아래 링크에서 확인할 수 있습니다.
scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
API Reference — scikit-learn 0.23.2 documentation
scikit-learn.org
'파이썬 > 파이썬 사이킷런' 카테고리의 다른 글
| 파이썬 머신러닝 / scikit-learn으로 k-최근접 이웃 알고리즘(KNN) 알아보기 (0) | 2020.09.26 |
|---|---|
| 파이썬 머신러닝 - Kernel PCA를 이용한 비선형 특성의 수 줄이기 (0) | 2020.09.13 |
| 파이썬 머신러닝 - PCA를 이용한 특성의 수 줄이기 (0) | 2020.09.13 |