반응형
파이썬 데이터 분석 / numpy arrary 생성하기
Numpy arrary 생성하는 방법
아래와 같은 방법으로 만들 수 있습니다.
1) np.array(data1) # data1의 자료형은 list 또는 tuple이 올 수 있습니다.
2) np.arange(20) # array + range가 합쳐진 것으로 보시면 됩니다.
3) np.linspace(-5, 5, 10) # start ~ end 까지 간격을 동일하게 만듭니다.
linspace(start, end, num) # num의 갯수만큼 데이터를 만들어 냅니다.
4) np.zeros([3,2]) # default 값이 0인 배열을 생성합니다.
5) np.ones([3,2]) # default 값이 1인 배열을 생성합니다.
6) np.empty([3,2]) # default 값이 없는 배열을 생성하는데, 이를 사용하면 반드시 초기화를 해주어야 합니다.
- rank : 배열의 차원
- shape : 각 차원의 크기를 tuple로 표시한 것
- 배열의 타입은 ndaaray 입니다.
예제
import numpy as np
data1 = [1,2,3,4,5]
print(type(data1))
print(data1)
arr1 = np.array(data1)
print(type(arr1))
print(arr1)
arr2 = np.arange(20)
print(arr2)
arr3 = np.linspace(-5, 5, 10)
print(arr3)
arr4 = np.zeros([3,2])
print(arr4)
arr5 = np.ones([3,2])
print(arr5)
arr6 = np.empty([3,2])
print(arr6)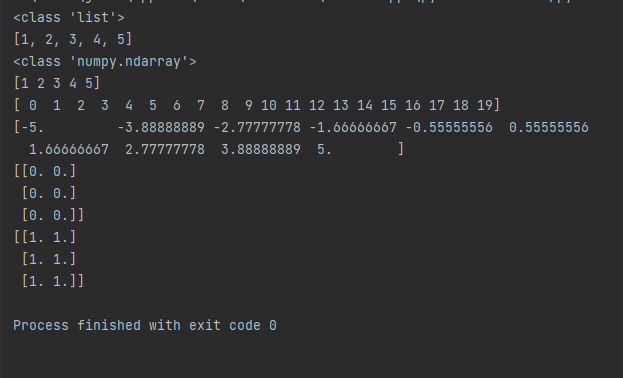
반응형
'파이썬 > 파이썬 데이터 분석' 카테고리의 다른 글
| 파이썬 데이터 분석 / DataFrame의 내용을 pyplot 모듈로 그래프 그리기 (0) | 2021.09.08 |
|---|---|
| 파이썬 데이터 분석 / Numpy 2차원 배열 전체, 행별, 열별 sum, average 함수 사용하기 (0) | 2021.08.30 |
| 파이썬 데이터 분석 / set 집합 함수 - 합집합, 차집합, 교집합, 대칭차 (0) | 2021.08.30 |
| 파이썬 데이터 분석 / pandas DataFrame 생성하기 (0) | 2020.08.24 |
| 파이썬 데이터 분석 / pandas DataFrame 열 추가 및 삭제 (0) | 2020.08.15 |








